Large-scale scientific data at your fingertips.
Multivac is a “Unified Big Data Analytics Platform”
launched in 2015. It hosts more than 360 billion web pages, social media, and
other
digital
content.
Multivac offers three main services: Multivac Dashboards
(interactive visualizations), Multivac API Engine
(real-time REST
APIs), and Multivac DSL (interactive
and
collaborative notebooks for Big Data).
“WORLD BEYOND DATA”
We've built scientific tools to dive into large-scale social media and Web data
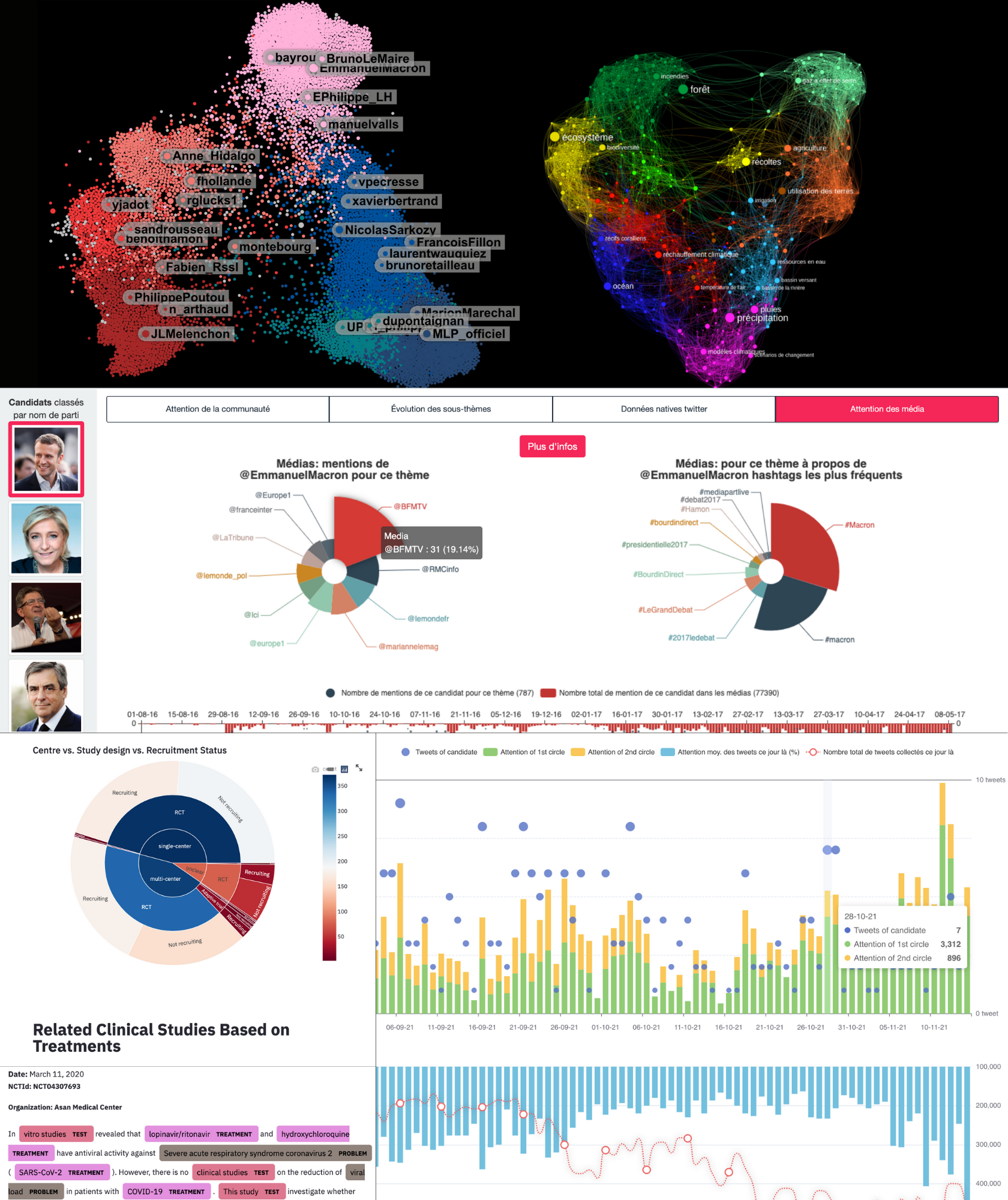
Multivac Dashboards
Interactive and real-time dashboards.
Multivac Platform offers curated dashboards to support common scientific use-cases among a variety of research topics such as Climate Change, international and French media, French political communities, Healthcare, and many more.
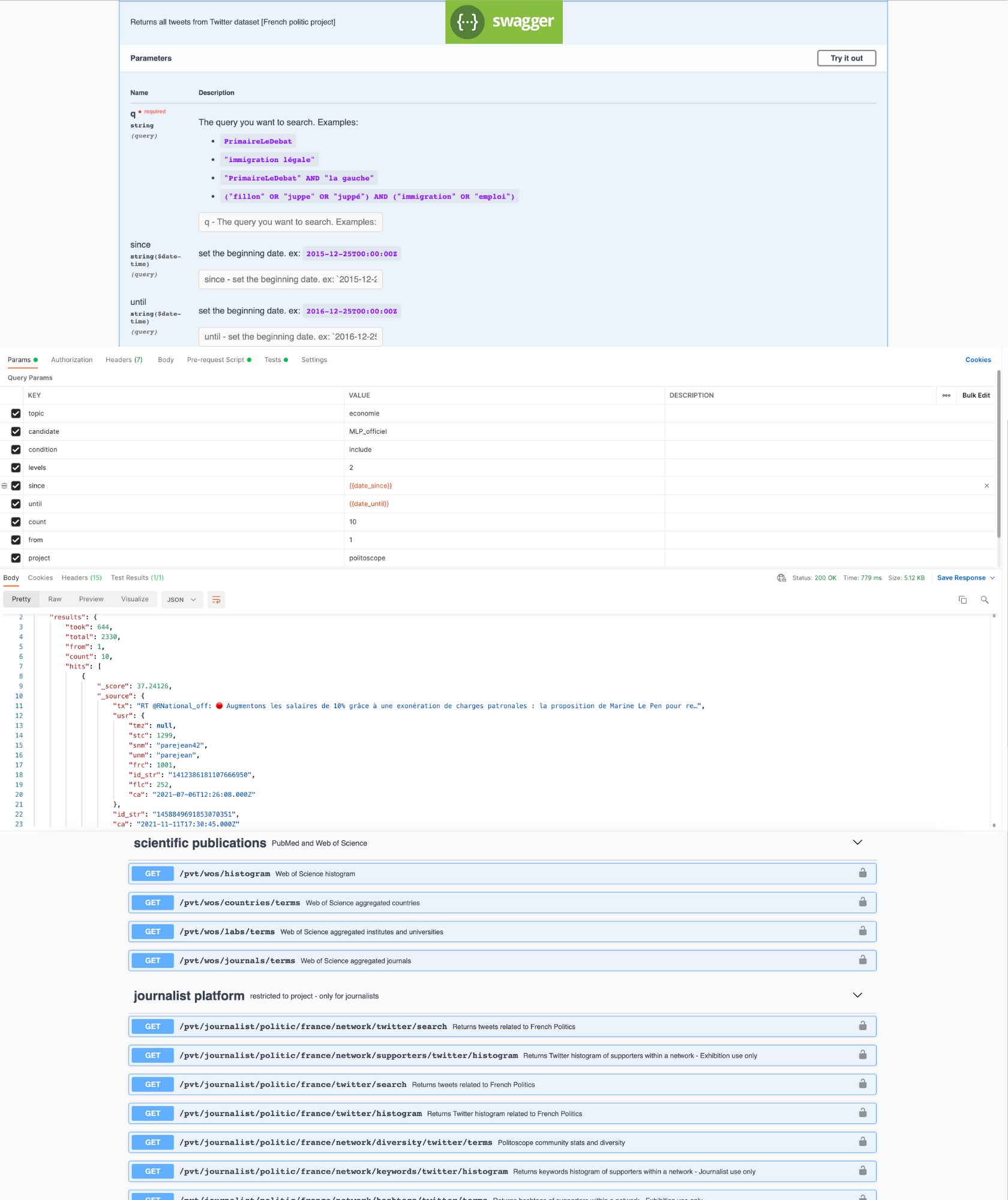
Multivac APIs
Design, develop, and build your new research projects.
The Multivac API provides access to data stored on Multivac programmatically in
unique and
advanced ways. The Multivac Platform offers a complete set of REST APIs to
access raw and aggregated
data in real-time to use in your research projects, build interactive or offline
visualizations, and
more.
Multivac uses Swagger to design, build and document all RESTful APIs. Swagger is
a powerful
open-source
framework backed by a large ecosystem of tools. It also follows the Open API
Initiative (OAI) to
standardise
how Multivac REST APIs are described.
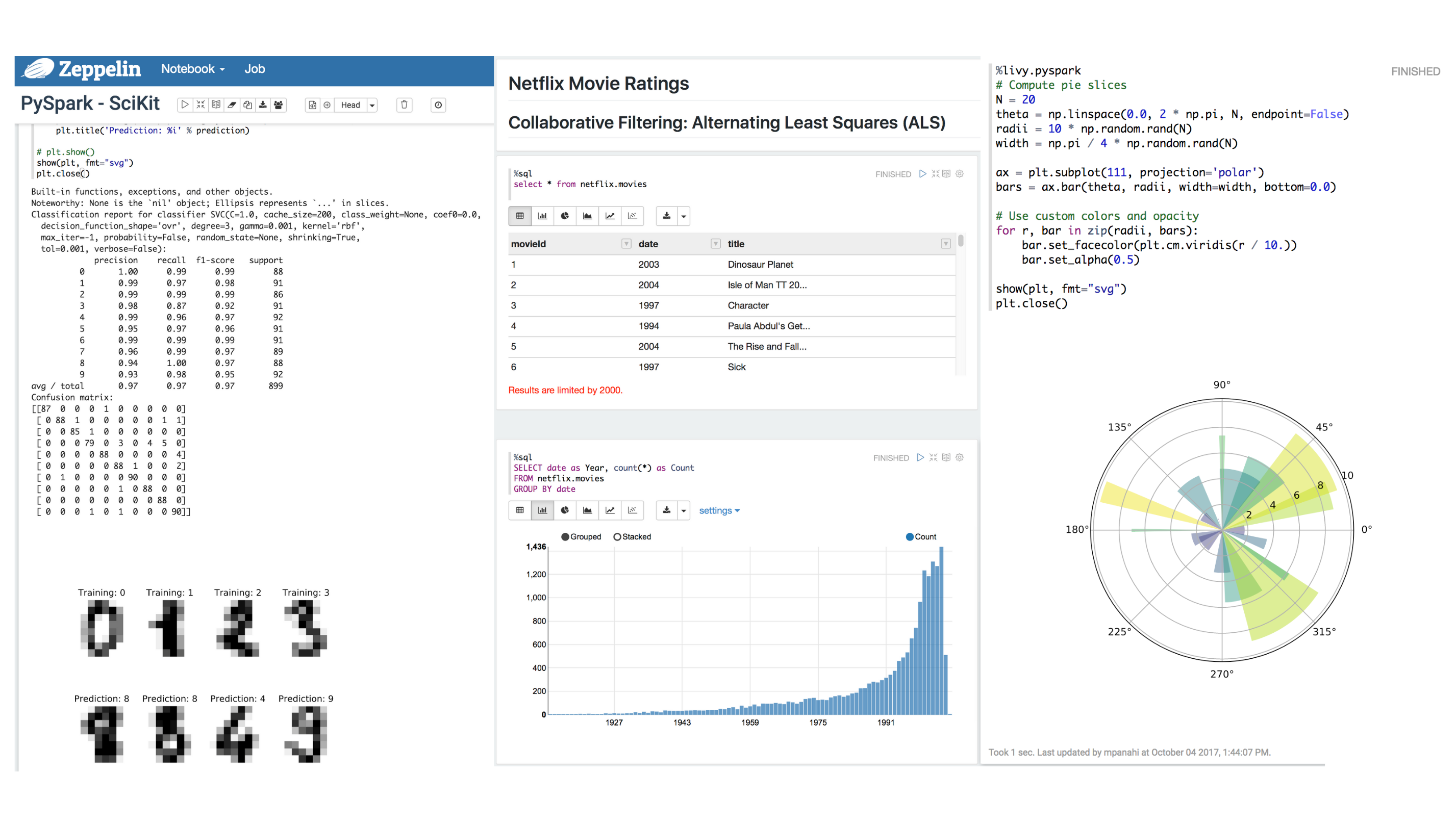
Multivac DSL
Interactive notebooks for Big Data.
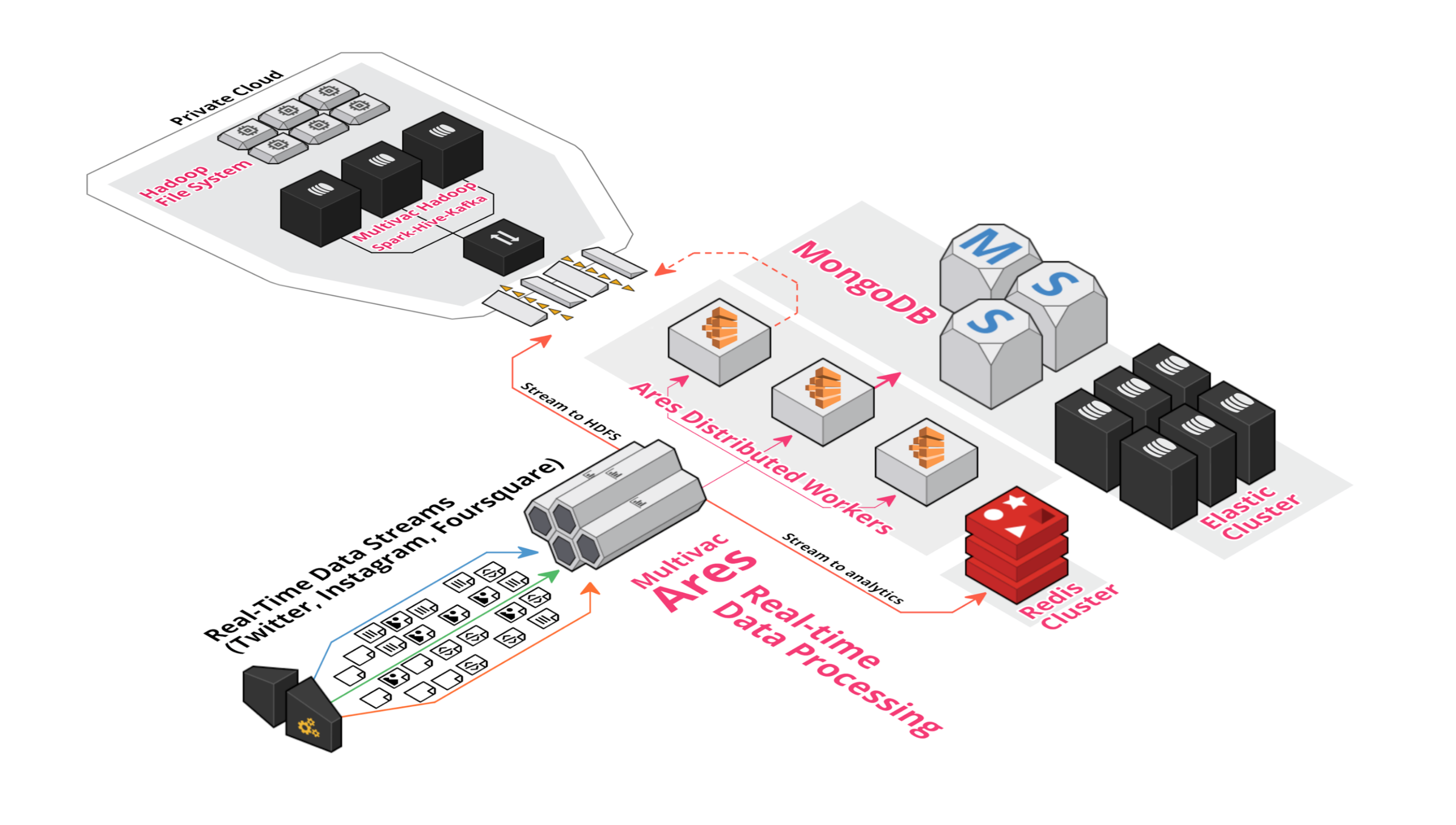
MULTIVAC Hadoop Cluster
We have designed and implemented an Apache
Hadoop cluster
over more
than 40 servers inside our private Cloud.
Both Hadoop and Cloud allow us for faster elasticity in scaling our
infrastructure and access to
components such as YARN, HDFS, Apache Spark,
and Apache Hive to run any number of
jobs in parallel
at scale over hundreds of millions of data.
MULTIVAC Hadoop Notebooks
Multivac offers interactive Hadoop notebooks by hosting
multi-users/multi-tenants Apache
Zeppelin and Hue.
In addition to notebook-powered analytics, users can submit their codes and jobs
over Multivac
Hadoop Cluster by using Apache Spark interactive shell and Spark submit or
Multivac hosted
interactive notebooks in Scala, Java, Python, R and SQL.
MULTIVAC Hadoop Open Data
Multivac is hosting large-scale datasets such as Wikimedia Pageviews (+337
billion), 4chan (+220
million),
or PubMed (+30 million) on its Hadoop Cluster (HDFS).
These datasets are accessible to all Multivac DSL users to run massively
distributed jobs against
them for their research projects.
Powered by Multivac
Multivac Showcase
We showcase some of our scientific projects built and powered by using the Multivac Platform. We used the Multivac API engine for real-time data visualizations and Multivac DSL for long-term aggregated studies.

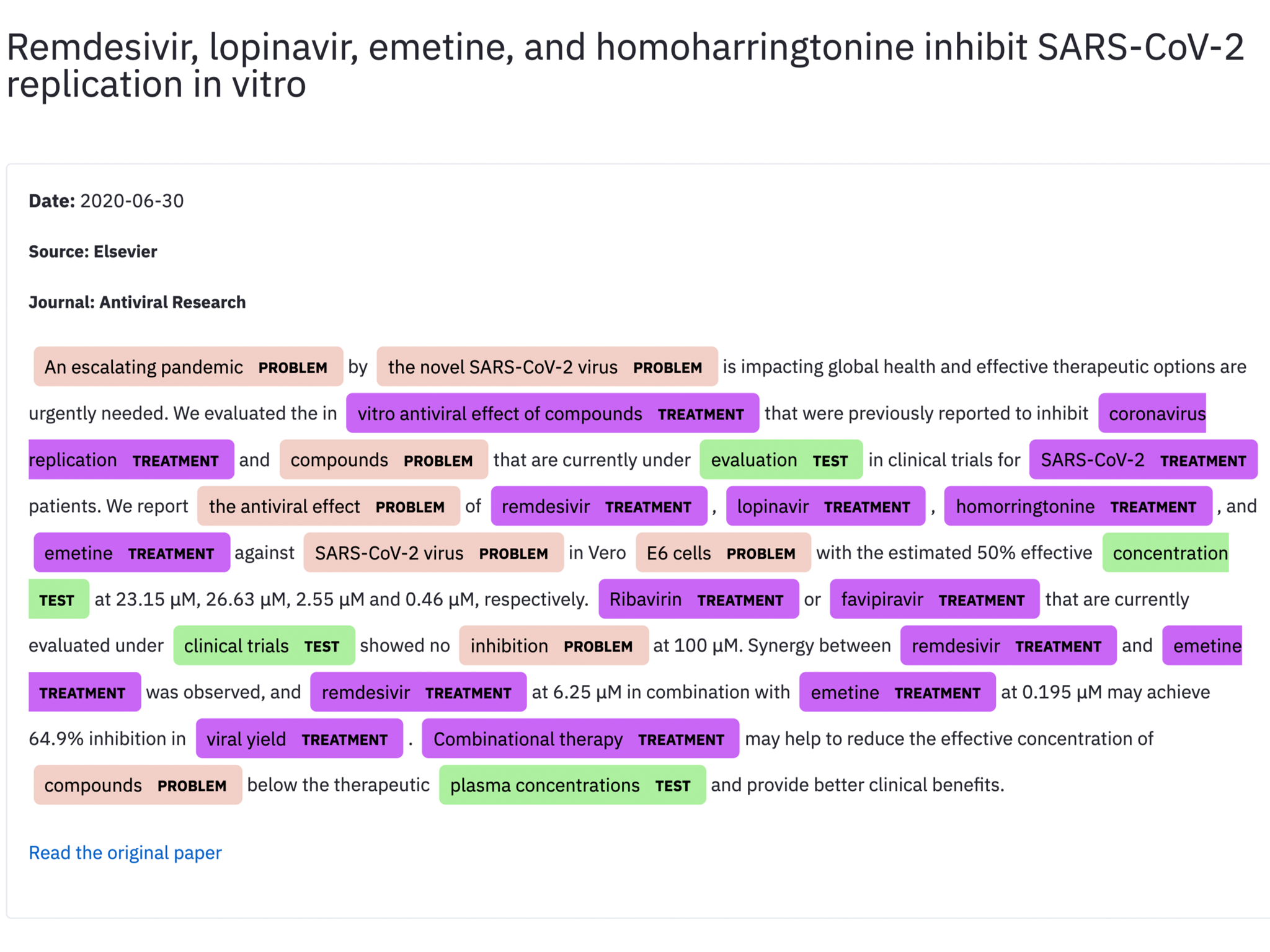
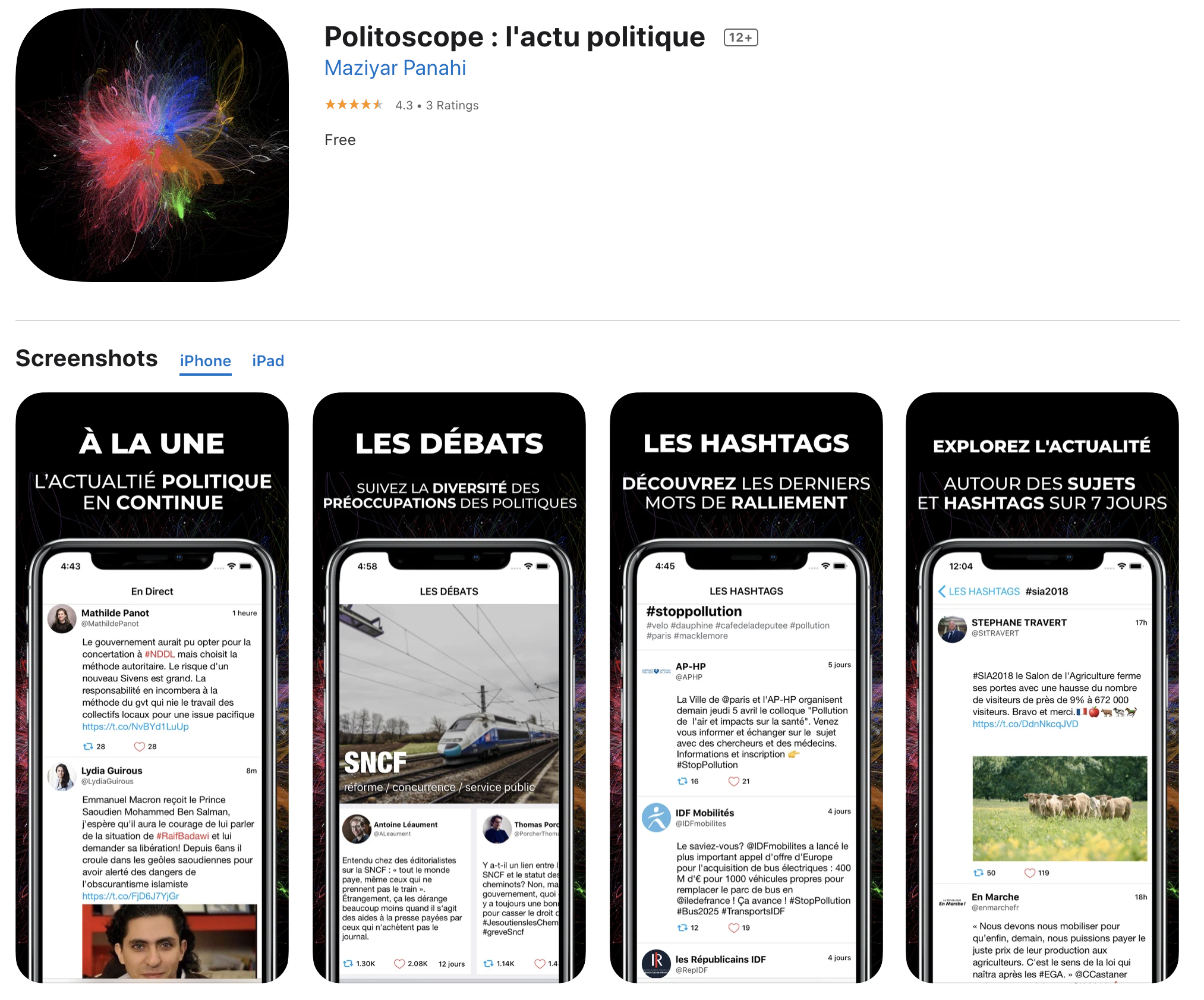

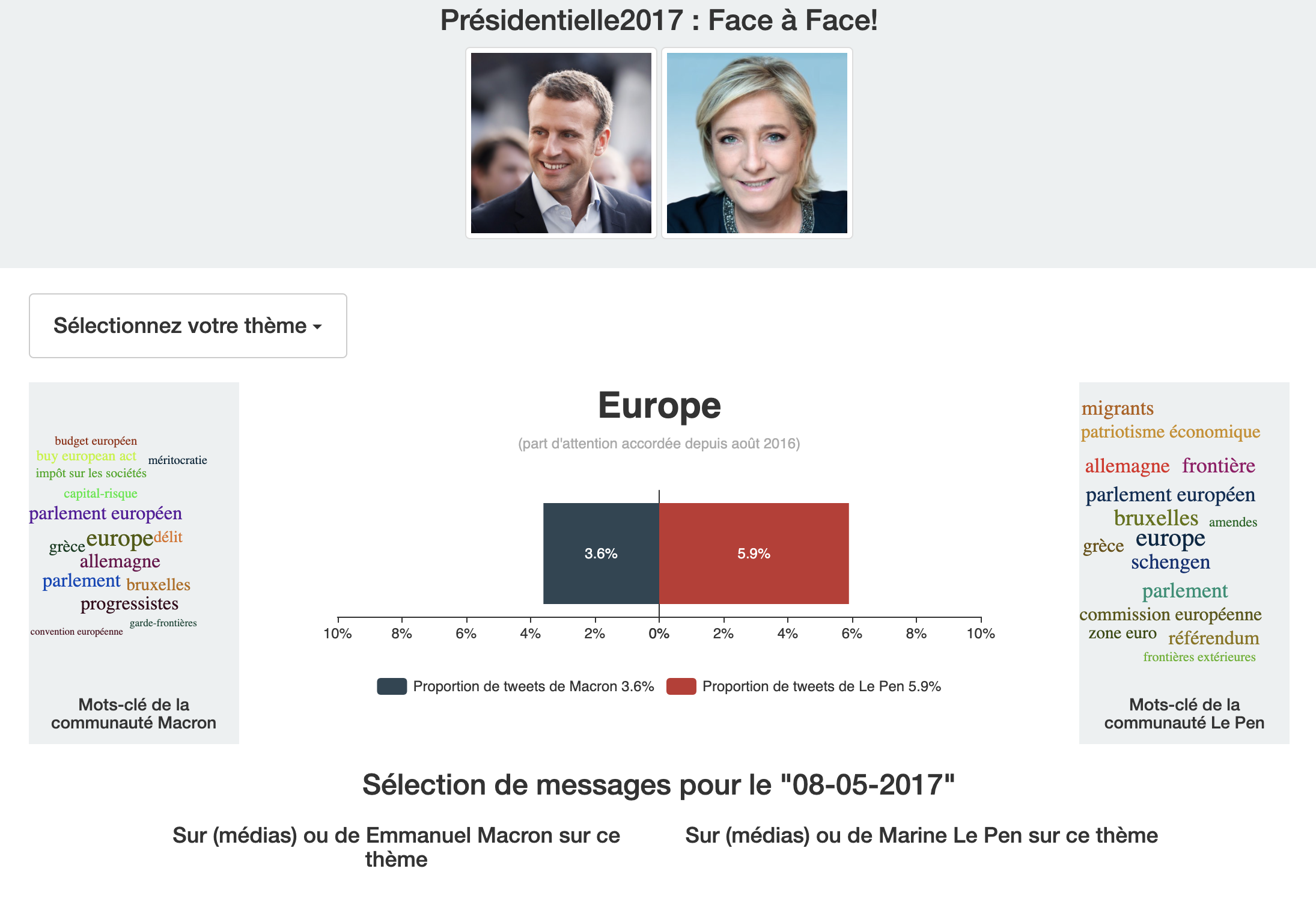



Credits.
HOST INSTITUTIONS

SPONSORS


ACADEMIC PARTNERS
ACADEMIC CONTRIBUTORS



COMMUNITY PARTNERS



TECHNOLOGY STACK











